 Web to code extension
Web to code extension Twitter
Twitter GitHub
GitHub Blog
Blog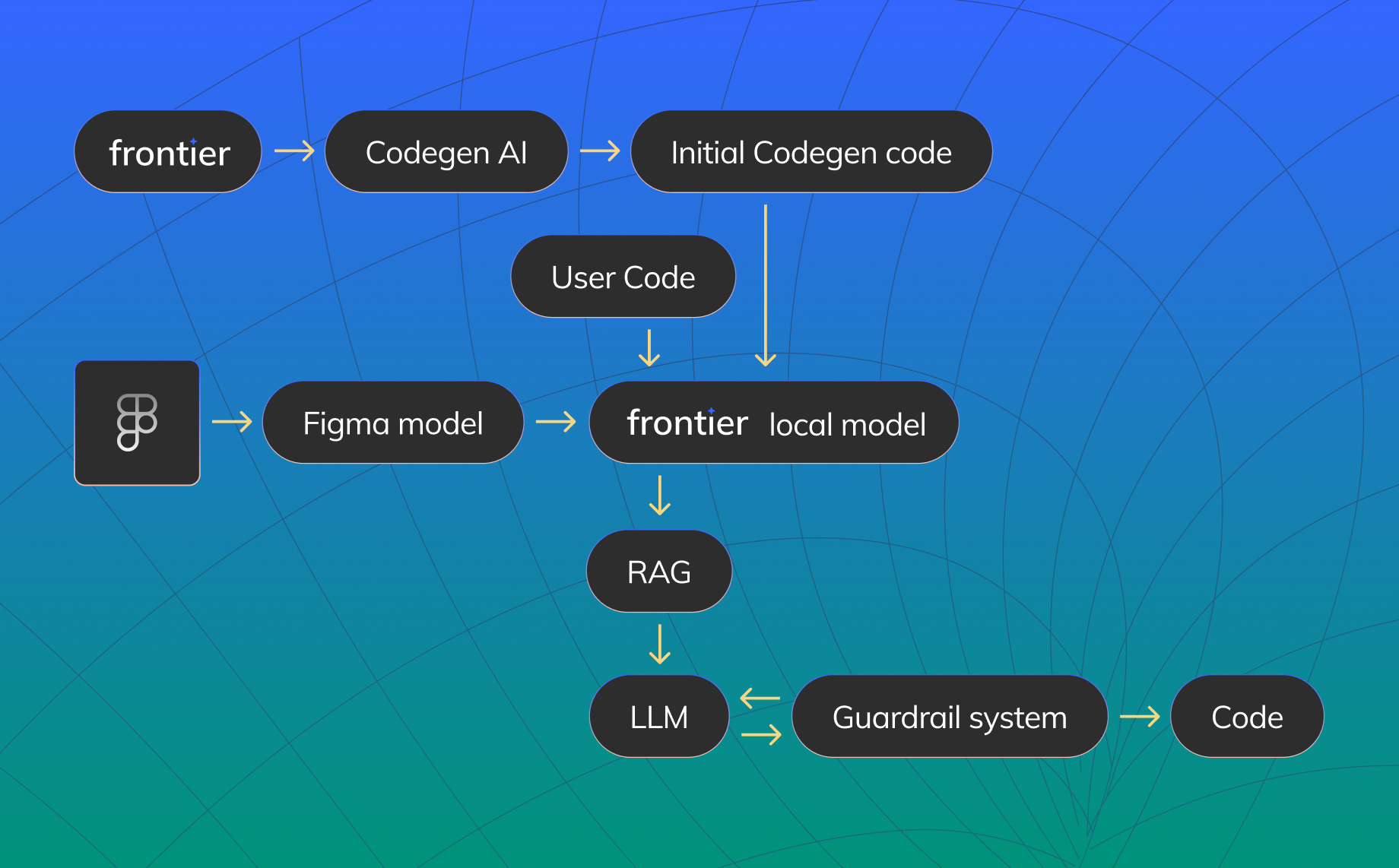
Guard rails for LLMs4 min read
Reading Time: 3 minutesImplementing Guard Rails for LLMs
Large Language Models (LLMs) have made a profound leap over the last few years, and with each iteration, companies like OpenAI, Meta, Anthropic and Mistral have been leapfrogging one another in general usability and, more recently, with the ability of these AI models to produce useful code. One of the critical challenges in using LLMs, is ensuring the output is reliable and functional. This is where guard rails for LLM become crucial.
Challenges in Code Generation with LLMs
However, as they are trained on a wide variety of code techniques, libraries and frameworks, trying to get them to produce a unique piece of code that would run as expected is still quite hard. Our first attempt at this was with our Anima Figma plugin, which has multiple AI features. In some cases, we intended to expand our ability to address new language variations and new styling mechanisms without having to create inefficient heuristic conversions that would be simply unscalable. Additionally, we wanted users to personalize the code we produce and have the capability of adding state, logic and more capabilities to the code that we produce from Figma designs. This proved much more difficult than originally anticipated. LLMs hallucinate, a lot.
Fine-tuning helps, but only to some degree – it reinforces languages, frameworks, and techniques that the LLM is already familiar with, but that doesn’t mean that the LLM won’t suddenly turn “lazy” (putting comments with /* todo */ instructions rather than implementing or even repeating the code that we wanted to mutate or augment). It’s also difficult to avoid just plain hallucinations where the LLM invents its own instructions and alters the developer’s original intent.
But as the industry progresses, LLM laziness goes up and down and we can use techniques like multishot and emotional blackmail to ensure that the LLM sticks to the original plan. But in our case, we are measured by how well the code we produce is usable and visually represents the original design. We had to create a build tool that evaluated the differences and fed any build and visual errors back to the LLM. If the LLM hallucinates a file or instructions, the build process catches it and the error is fed back to the LLM to correct, just like a normal loop” that a human developer would implement. By setting this as a target, we could also measure how well we optimized our prompt engineering, Retrieval-Augmented Generation (RAG) operations and which model is ideally suited for each task.


